Since the year 2000, we at Silicon Publishing have carried on a tradition we first encountered from our former life at Bertelsmann Industry Services (a now defunct company with its own 20-year history): database publishing. We automate the flow of data through templates, producing the entire spectrum of documents that can be generated from data:
- Catalogs
- Directories
- Financial statements
- Insurance documents
- Report cards
- One-to-one marketing pieces
- Practically anything you can think of…

The diversity of “data-generated documents” has surprised me ever since I started working in this business. 20 years ago, we were still producing internal phone directories for companies such as Chevron and Mobile, large organizations that spewed forth paper to communicate information before the web took over.
Today, we might compose “print” output for a company like Royal Caribbean, who spits forth millions of cruise booklets per year, and even though almost none get printed, the documents are paginated to be ready to print if needed, and are sent to devices with “readers” that make print-like output viewable (without ever having to be printed). Some day we may attain a “paperless” world, and even then we will still be spitting out documents with a very similar approach. Metaphors from print go right into the web, as do underlying core technologies such as typography and imaging.
Yes in some ways print and web remain diametrically opposed, particularly the “fixed position” mindset of print designers vs. the inevitable (and increasing) “responsiveness” that good web designers have intuition for, but probably 50% of our technology applies to both forms of rendition equally. Honestly we would love to see print and web converge completely some day, and work with the W3C towards this end, but we don’t see this happening quickly and our focus on the most precise, refined, high-quality print possible leaves us specializing in Adobe InDesign Server for the foreseeable future. We love this piece of software.
What is Silicon Paginator?
Silicon Paginator has had various names over time, but it is essentially our ever-evolving codebase for flowing data through templates, primarily Adobe InDesign templates. In 2005, we called it our “XML Formatting Engine” but in reality it has nothing to do with XML, since we just started out with an internal XML representation of whatever flowed in. When our Silicon Designer product became popular in 2009, we renamed the XFE “Silicon Automator”, but soon after decided that “Paginator” was a better name, less likely to be confused with Apple’s “Automator”.
Data
XML is one form of input, but not the only – Silicon Paginator can work with it, or almost any other form of structured data as input, whether XML, relational data, Excel files, CSV, JSON… nearly any form of input that adheres to a structure. Sometimes it is very simple. For example, the data for a set of business cards might just be a flat, basic Excel table. Sometimes we work with nested structures, and flexible schemas with layers of abstraction. Another example: parts catalogs for manufacturing may have a different set of data points for each product, so the field names on any given page could be unique. Often the data we receive is not optimized for our purposes. Many organizations are stuck with “what we can get automatically from the system” and so, in those cases, are we.
Whatever data we receive, we normalize/de-normalize it into a structure that we are comfortable with. When working with InDesign Server, it is best to provide as precise a stream of text flowing through the pages as possible, so we can either inform the client of the direct input, or define a consistent intermediate structure. And sometimes we must adapt to one that is mandated for us.
Templates
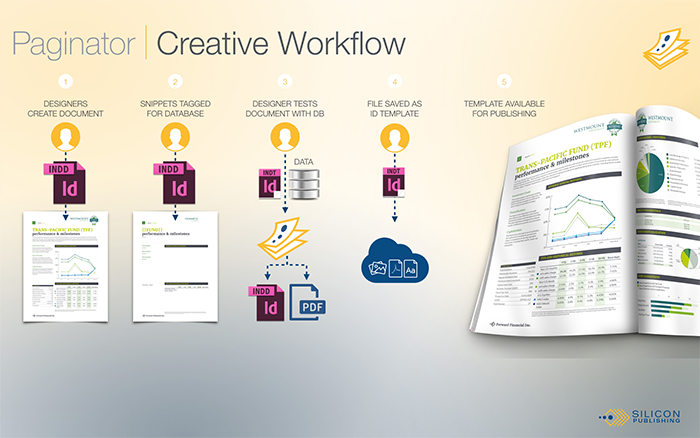
Beyond the data, we require data-aware templates. These are created with Adobe InDesign: while we can provide various in-app tooling to make it easy to set templates up, the fundamentals of our template setup can usually be accomplished without such tools. If you download this file, you can find some public template-setup guidelines for our web-to-print application, Silicon Designer, which are not all that different from a typical Paginator template setup guide.
A template for Silicon Paginator is simply an Adobe InDesign file, which includes the various styles (character styles, paragraph styles, table styles, object styles, etc.) and page geometries of the document (or document section) being produced. Templates typically have some metadata – text in brackets, names for layers or labels on text frames, etc., that will tell the pagination process how the data flows through each InDesign template using the styles and geometries defined in the template.
We also have CC Extensions, C++ plugins, and other forms of InDesign extensibility, that for example let the user drag variables or data-aware snippets onto the InDesign page. Given the broad array of use cases and workflows, the level of tooling ranges from zero to idiot-proof, but such tooling is not a requirement: it simply makes template creation very easy, even with complex workflows.
Output!
In simple Paginator applications, all that is needed is a data source and a ready-to-go template. Our Paginator, triggered from a button on a web page or a RESTful Web Services call, will ingest the data, run it through the templates, and emit the highest-quality print-ready output. It can be quite simple, the extreme case being “mail-merge” document types, where you are merely resolving text and possibly image variables as well. Yet it can also become quite challenging: a one-to-one marketing campaign, for example, may have complex rules that swap layers or InDesign snippets based on conditions; or a parts catalog may include 4 different auto-generated indices (sometimes these take up more space in the catalog than the main content).
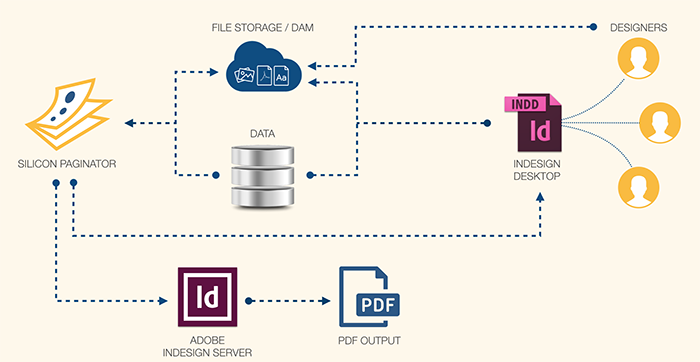
Rules, a Potential Third Input
In more complex applications, there is another input to the system: a rules file of some sort. Think of a manufacturer producing catalogs, with the requirement to publish 300 different variants: one for region X, one for Distributor Y, etc. They may have prices that differ or are omitted, they may have different static matter included, varieties of branding, document size, etc. In this situation, we let the client maintain a rules file. It can be an online database, an XML or JSON file, Excel or tabular format (we need to be flexible, given the diversity of verticals that we serve). In any case, we have a rule or set of rules per document being emitted, and Paginator will iterate through these, producing each document according to the appropriate ruleset.
Vertical Markets for Paginator
Companies find out about us when they look around for “InDesign Server”. Just like InDesign itself, the market for InDesign Server is extremely broad. Since we didn’t create a “Silicon Catalog Creator” or a “Silicon Quarterly Financial Report Creator” but rather a generic product for any form of document, we cover the gamut of anything one would need generated from data. We have seen the vast spectrum from casinos delivering highly-personalized marketing pieces, to furniture catalogs to insurance contracts to… whatever comes in tomorrow.
Our tactics with Paginator do not differentiate dramatically along vertical lines, although it is true that different verticals tend to pull from different sections of our code. Direct mail is often more focused on relational data, while insurance documents may have rich textual content (HTML or XML) flowing through InDesign stories, and catalogs often have hierarchical data sets with flexible schemas. To see Paginator in a real-world context, take a look at these three verticals we’ve worked in:
Manufacturing – Product Catalogs
One of the most complex and challenging forms of pagination comes with catalogs, and we have set up catalog automation for some of the largest retailers and manufacturers in the world. Manufacturing catalogs are typically more data-intensive, while retail catalogs are typically design-intensive. In the world of manufacturing, we have the following challenges:
- As I mentioned above, it’s not impossible for every different part in a catalog to have a completely different set of attributes. The data schemas we use for catalogs tend to be complex.
- Catalogs are often index-intensive and may have a great deal of cross-referencing among sections of content.
- As product catalogs are still physically printed to this day in many situations, fitting everything on the page effectively is a valuable functionality, especially given the shorter print runs and cost involved.
- Product catalogs often benefit from rules-driven variations or control via a web interface. We have a robust interface for managing the sections of a product catalog online.

When our magic is done, we’ve provided the client with sample initial templates and instructions on how to change templates to accommodate changes in formatting, flow and data elements. This ensures that they have a way of managing sections of a document, inserting static matter, sequencing indices and TOCs, and rendering/sequencing document sections of data-generated pages. They can manage the document sections by means of either an XML file that will determine the sections of an InDesign book, or via a web-based front end.
Catalog automation is one of the rare disciplines in which manual intervention is sometimes a feature, not a bug. If you are only creating a few catalogs every quarter, then you might have time to intervene manually, putting that magical finishing touch on a catalog. This becomes exponentially less desirable as quantities increase (most of our Paginator implementations, even product catalogs, are “lights out”) and this is one situation in which InDesign Server shines as a rendition engine. With InDesign Server, we can always return the art file(s) generated from automation to the client. Post-processing is easy, and we often provide scripts to regenerate indices, cross references and TOCs after edits are complete.
Financial Services – Statements
Another common vertical for Paginator is financial services, as so many institutions are obligated to report monthly, quarterly and/or annually, and financial statements are typically entirely data-driven. Often they are customized according to a specific plan or company, or personalized for a specific recipient. Following are some characteristics of documents in the financial space:
- Charts and graphs are extremely common. We can automate charting directly with InDesign Server, although more commonly we reference graphics generated by tools such as Highcharts.
- Tables are also extremely common. This is a document object that traditionally represents a time drain when working with InDesign Server, yet we have recently made breakthroughs in the speed of table rendition.
- Financial documents are on the mission-critical end of the spectrum, and like coupons or billing statements they really want the data to be correct; thus automated validation that all text printed correctly is often part of the process. One example of this is in the export of data elements from the InDesign output being checked against incoming data.
- Financial documents are often less a flow of content across pages, than a fairly fixed set of objects on a page, either in fixed positions, or with the requirement that a specific number of sections or elements fit on a given page.
The fact that financial documents are often composed of a number of small chunks of content, (such as the table showing fund values over a period of time that is coupled with a corresponding chart), fits perfectly with our work with “data-aware snippets.” An InDesign “snippet” can be any arbitrary chunk of content, such as a table and its introductory text, a chart and its callouts/key, or any collection of page items, that together can be considered a meaningful document component. We provide ways to make such document components able to ingest content, employing the same techniques common to more general uses of Paginator. Once again using Adobe InDesign proves to be advantageous, while snippets are a best practice for this sort of document – really the ideal way to manage content. Data-aware snippets can also be stored in DAM systems such as Adobe Experience Manager.
Unlike catalogs, it is rare for financial services organizations to have an appetite for very much manual post-processing. Given the volume of throughput and its mission-critical nature, the lights-out process is usually augmented with automated validation and backed by manual spot-checking to ensure the accuracy of the process, rather than cost-prohibitive manual reviews of the entire body of output.
Travel & Hospitality – Itineraries
The travel industry represents one of the classic use cases for Silicon Paginator. If you book a cruise on Royal Caribbean Cruise Lines, for example, you will soon receive a cruise booklet, containing all of the information you need to know in advance of your cruise. Itineraries, details about ports of call, confirmation of those traveling with you; everything is neatly integrated into a personalized cruise booklet. Travel documents such as this have the following characteristics:
- At a high level, there is a process of content aggregation. There may be fields in the data that trigger inclusion or exclusion of certain pages or chunks of content, which may be modified given the specific recipient. You don’t need a section on frostbite if you are visiting Tahiti. The first step in pagination is this identification of the sequence of document sections.
- Content is often delivered as flowing text, sometimes across a sequence of pages. The rich formatting of such text may be found in the form of HTML or XML, out it might come from rich text fields in a database, or those referenced in a DAM or conventional file system. Silicon Paginator has robust capabilities that map style markup to InDesign object styles, resulting in very powerful rendition for text flows.
- As with financial statements, tables are also quite common.
- When documents contain flowing text, there is often a design goal of making the document appear to be hand-crafted. In response, we have evolved rules-driven composition that can accomplish this in an automated fashion. For example, the number of records in a table can determine whether it can be slightly adjusted to fit onto a page, or if it must be spread across two pages with filler images or advertisements. Either way, the result is the appearance of perfect pagination.

The goal here is not to put designers out of work: instead, the designers working on an automation project such as Royal Caribbean are empowered to control the design intent of the entire process. Because templates are built with standard InDesign styles and geometries, template design is very powerful. By simply changing the fonts in paragraph and character styles, or the swatches of a document, radical changes in the look and feel are possible. Going beyond this, we also offer the designers new ways to map to data that allow for changes in database schema or page flow.
Going Forward
As we evolve the Silicon Paginator market, we may actually take some focus on specific vertical markets, yet probably more for the marketing than for significant vertical-specific development. We have at our disposal the power of a very wide array of functions and techniques to handle everything that comes up in virtually any document type. For example, the text formatting of catalogs is sometimes dumbed down to support limitations of source data, yet in our case we can offer truly robust text formatting: once this is supported in the system of record, it can be a very positive feature of the output.
We are grateful that we chose Adobe as a partner long ago, and specifically that we have relied on Adobe InDesign Server as our composition engine since 2005. We bet a long time ago that one day InDesign Server would go fast enough to support even those use cases with extreme throughput (such as transactional statements and large variable data print jobs), and that day has arrived.